Back when I was a younger man and crossing the country playing music for screaming crowds (really, making occasional weekend drives to Wisconsin to play at a bar for six other people and drink some free Blatz), I kept having the same frustrating conversation over and over. It went something like this:
Person: Oh cool, you play in a band? What kind of music do you play?
Me: Well it’s sort of like an alt-pop kind of thing. Maybe sort of like rock too I don’t know.
Person: Alt-pop? I have no idea what that means.
Me: Hm. Well someone once told me we sounded like if Cat Stevens joined the New Pornographers and they all decided they just wanted to make people dance.
Person: … I can’t even imagine what that sounds like.
Me: Coincidentally our lead singer actually did recently convert to Islam, too.
(Person wanders away, bewildered)
For a person with mildly debilitating social anxiety, this was pretty stressful. It’s not actually why I don’t play with that band anymore, and I didn’t actually decide to learn data science solely to answer this question, but for the sake of this post’s narrative let’s pretend that’s how it went. (And for the record, that weirdly specific description is bizarrely accurate.)
Anyway, onto the data science!
The Free Music Archive is a collection of more than 100,000 downloadable music tracks with associated metadata that includes various sonic features extracted from the tracks via a relatively new Python library called Librosa. The majority of these tracks are categorized into 16 top-level genres, resulting in a very large dataset well-suited to building a model for categorizing music into genres based on its spectral and rhythmic features.
After downloading this dataset from the FMA GitHub and cleaning up the files (they were in pretty great shape, but for simplicity’s sake I removed all of the tracks that had more than one top-level genre and used only the nine largest genres in my model), I trained and tuned a variety of supervised learning models, settling on a scikit-learn XGBoost model as my best performer, achieving about 60% accuracy across 9 possible genres (much better than the 11% accuracy that would be obtained by random guessing). However, this model took hours to run on my 40,000-track training set, making tuning laborious. Furthermore, my goal was to develop a web app that would use the model to determine the genre of any uploaded mp3 file, for which I really needed a more efficient model.
To that end, I ran a Principal Component Analysis to reduce my 500+ features to 15 features. This didn’t sacrifice much information, as my 15 features captured just about all of the variance of my original 500+ features (greater than 99.99%). This small information loss resulted in huge efficiency gains – the model ran in less than 20 minutes compared to several hours previously.
In order to finally be able to answer the question about what my band sounded like, I pickled the model and my PCA transformation and built a webapp via Flask that allowed a user to upload an mp3 file, then used Librosa to extract the necessary features from that file, transformed the features via my existing PCA transformation, and then ran the transformed features through the model to output the mp3’s genre. For a little extra fun, I had the model output its level of confidence in its categorization (in the form of the specific probability it assigned to the most likely genre).
After much wrangling with Flask, my app gave me the information I needed years ago: it is 75% likely that my band is rock! Glad that’s settled after all these years.
I’ll be posting a link to the web app here soon – it’s going up on AWS as soon as I’ve made the upload process secure enough for public use.
In a follow-up post I’ll describe some of the challenges I faced due to the imbalanced categories in my training set (between 14,000 and 1,200 tracks per genre) and how the presence of multiple tracks from many artists caused oversampling to fail to compensate for this imbalance.
As with my earlier project, my None-More-Black repo has more findings and code from this project, and will host my continued data science investigations into music genres and linguistic characteristics.
Bands make linguistic choices when writing lyrics, naming songs and albums, and choosing the name of their band. Hopefully, these choices signal the band’s aesthetics to potential listeners so that they find their audience.
I tend to have strong positive reactions to certain words that signify an aesthetic I am likely to enjoy (really, anything that sounds like Dungeons and Dragons, especially if there’s a wizard involved). I got to wondering if good album names could actually help facilitate connections between bands and potential fans. But how to quantify the aesthetic?
Thankfully, Iain Barr has already created a “metalness index” for 10,000-some words based on their relative
frequency in metal lyrics compared to other forms of writing (full details in his blog post here.)
I used Iain’s metalness index to create metalness scores for approximately 7,500 metal album titles as well as
for the song titles on each album and the name of each band, and then ran a series of linear regressions to
determine if metalness scores could predict the ratings that metal fans give to those albums.
Before modeling, I checked to make sure that the metalness scores passed the eyeball test. I actually calculated them a few different ways – using the mean metalness score of the words in the album titles meant that single-word titles (or titles with only one word in the index) had more extreme scores, and the top metalness list was comprised of albums titled “Burn” (the most metal word in the index). Using the sum of metalness scores privileged long album names, which led to some slightly silly results. I was most happy with the ratings derived from a compromise method that divided the sum of metalness scores by half of the number of words in the title. Here’s what they looked like:
The five most metal album names:
Rage Of The Blood Beast
Sword Of Revenge
Tears And Ashes
Burn Me Wicked
Bury The Ashes
That seems pretty legit, doesn’t it? The first two speak to me more than the other three, but the right ingredients are there for sure, and we have a variety of highly metal words represented.
The five least metal album names:
Crumb’s Crunchy Delights Organization
Doomsday For The Deceiver 20th Anniversary Special
Nato Per Ragioni Ignote
Carte Blanche
District Of Dystopia
These also look about right to me. It’s a little weird that the third album is in Italian (it translates to Born for Unknown Reasons), but the metalness index interpreted the first word as “NATO”, which is pretty un-metal (metalness score: -3.66). The last entry illustrates a quirk of the index: un-metal scores are negative, and have a larger absolute value than the highest metalness scores (scores range from -5.99 to 4.15). District is a fairly un-metal word (-4.35), whereas dystopia, despite sounding pretty metal, was not in the index at all (but even if it was, it could not have balanced out the score for “district”).
So, since it looks to me like these metalness scores are representing something, back to the question at hand – does the metalness of album titles (or song titles or band names) have any relationship to the ratings of that album?
…
No. Nuh-uh. Not even a little. (The “best” model using only metalness scores accounted for approximately
0.1% of the variance in album ratings.)
…
(I’d probably give a bonus point per wizard myself, but I seem to be in the minority.)
In other words, it doesn’t seem to matter what you name your band, your album, or your songs, people are going to like your music (or not) based on less-obvious factors like, you know, if it’s any good or not. So you may as well name your album The Committee Chairman’s Particularly Literary Secretary (the 4th, 9th, 1st, 16th, and 3rd-least metal words in the index).
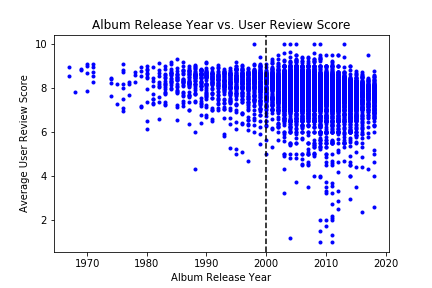
Still, I learned a few things during my investigation into the album ratings on metalstorm.net. For one, user ratings tended to be higher for albums released in earlier years:
However, that vertical line represents Metal Storm’s founding in 2000 – and if you look at the albums they reviewed retrospectively, they are nearly all classics by the likes of Black Sabbath, Led Zeppelin, and Iron Butterfly (that’s right). Release year post-1999 didn’t have nearly as much of a relationship to album ratings.
(If you’re wondering about that low rating in the late ’80s, that would be when a renowned extreme metal band named Celtic Frost tried to get some of that Bon Jovi money by recording a glam album. It … did not work.)
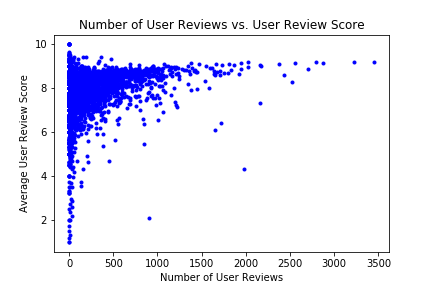
The only other bit of album metadata that seemed related to review scores was the number of users reviewing an album:
It seems pretty self-evident that users would be more likely to review albums that were widely acclaimed, even if they themselves hated it.
(If you guessed that the two albums that hundreds of reviewers nearly universally hated were the album Metallica recorded with Lou Reed and their much-maligned St. Anger, invisible oranges to you.)
My None-More-Black repo has more findings and code from my investigation of how metalness scores (don’t) relate to album ratings. Stay tuned to that space for more heavy investigations.